Support vector machines with Scikit learn
Sun, Mar 6, 2016Support vector machines are supervised learning models used for classification and regression. For a classifier the data is represented as points in space and a SVM classifier (SVC) separates the classes by a gap that is as wide as possible. SVM algorithms are known as maximum margin classifiers.
To illustrate the SVC algorithm we generate random points in two dimensions arranged in two clusters. This is illustrated in a Jupyter (IPython) notebook in this repository.
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.60)
from sklearn.svm import SVC
clf = SVC(kernel='linear')
clf.fit(X, y)
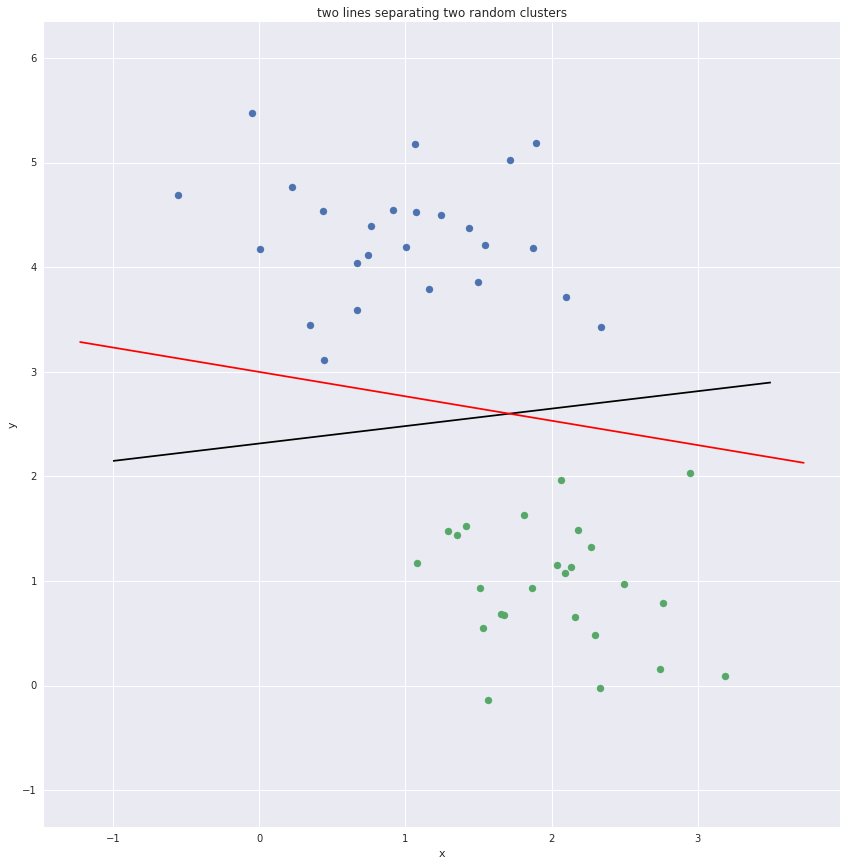
Two lines separating two clusters
Multiple lines can be drawn to separate the clusters. The black line is preferred to the red line as there is a larger margin between it and the nearest points.
Some of the points nearest the boundary are known as support vectors. They margins and the support vectors are plotted below.

Support vectors
Support vector classifiers are linear classifiers. For datasets that are not linearly separable they do a poor job.
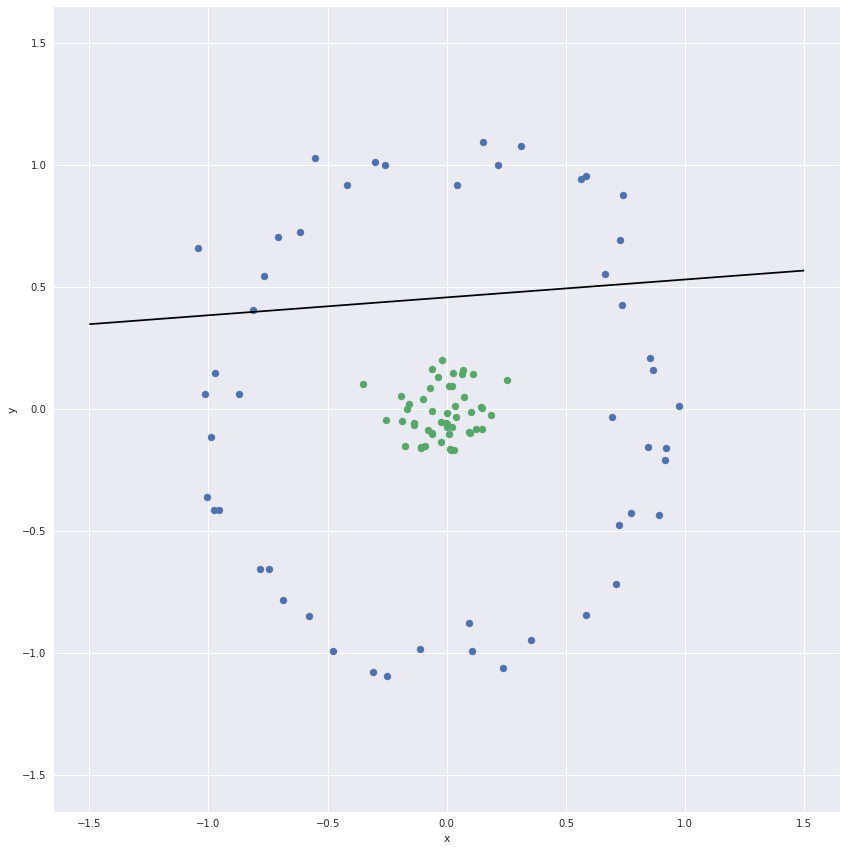
Non-linearly separable data
To create non-linear boundaries we could convert this two dimensional data set to higher dimensions. For example we could add the distance of the points from the origin as the third dimension. The two clusters will then be easily separable.
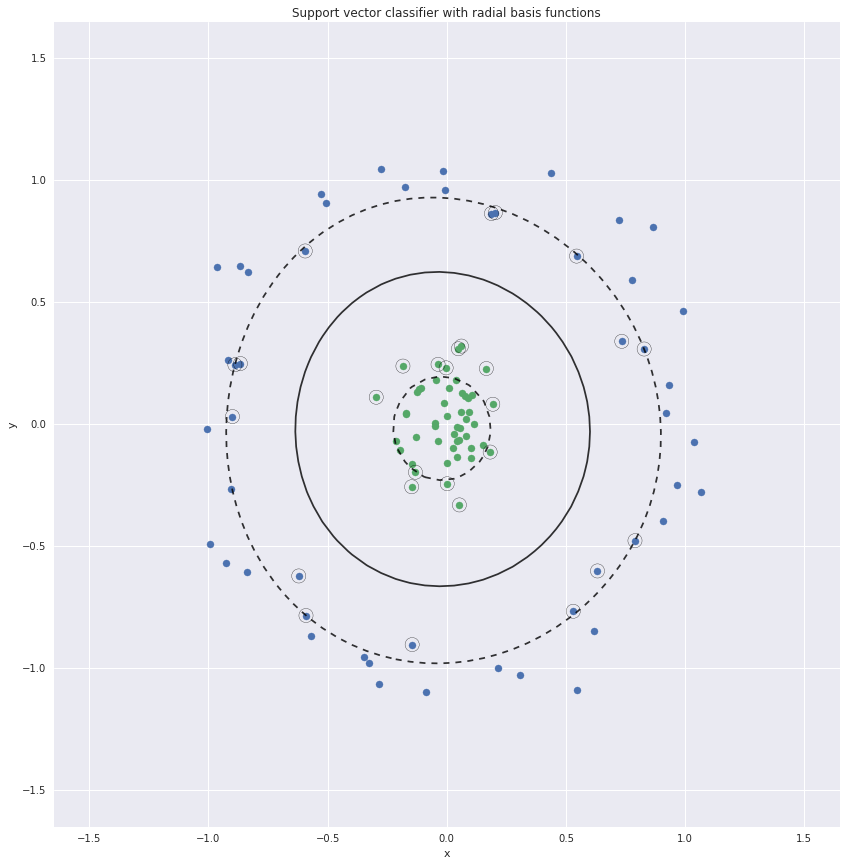
Radial basis functions for SVC
Another example with non-linearly separable data.
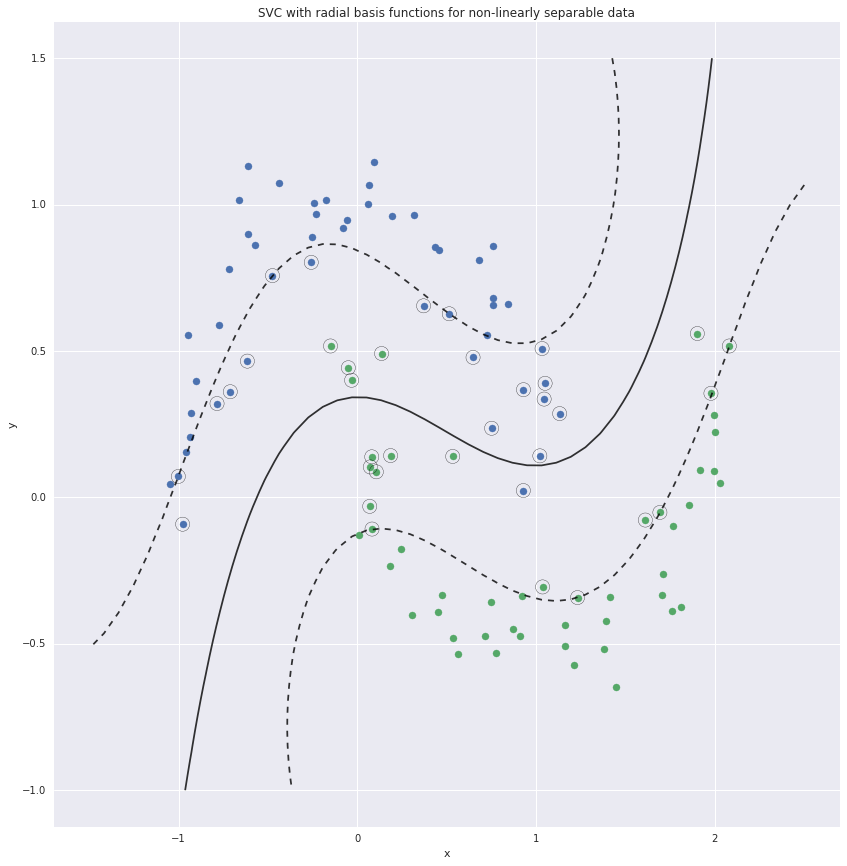
Radial basis functions for SVC