Random forests using Scikit-learn
Sun, Mar 20, 2016Random forests is an ensemble learning method. Ensemble methods use multiple learning algorithms to obtain better predictive performance than could be obtained for any of the constituent learning algorithms.
Random forests work by constructing multiple decision trees and combining the trees. The algorithm was developed by Leo Breiman and Adele Cutler and “Random Forests” is their trademark.
Random forests correct for decision trees’ habit of over-fitting to their training data set.
This Jupyter notebook contains all the code used to plot the charts.
To demonstrate the tendency of decision trees to overfit the data we predict the species of Iris using just two features: sepal length and petal width. The species are shown in a scatter plot in different colors.
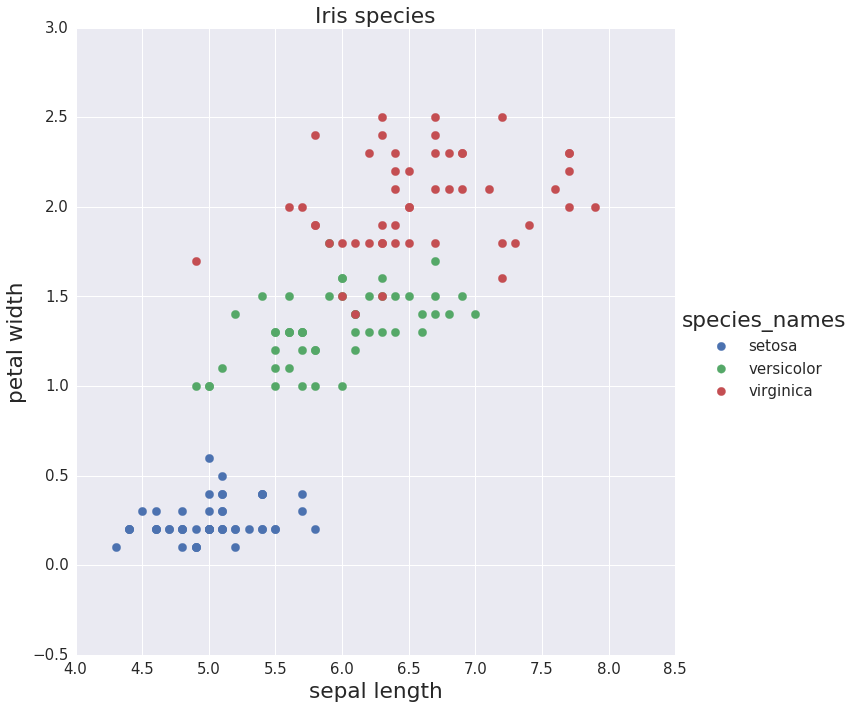
Scatter plot of Iris species
The graphs below show three Iris species using three different colors and the shaded regions predicted by the decision tree using lighter shades of the same colors. Each of the three plots in the set uses a different random sample made up of 70% of the data set. The decision tree boundaries are different in each case. This is an indication of over-fitting.
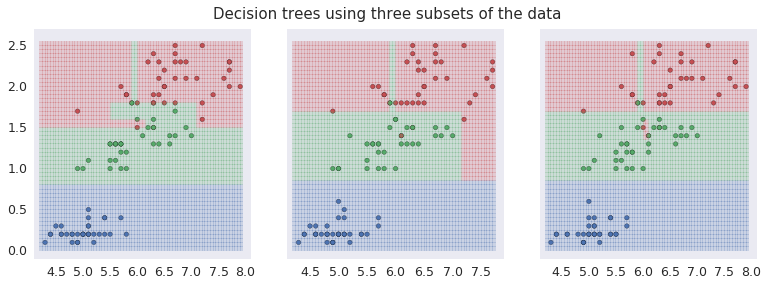
Using decision trees to predict Iris species
A similar plot shows a Random Forest Classifier with 500 trees each time used to select various sub-samples of the dataset. This controls over-fitting.
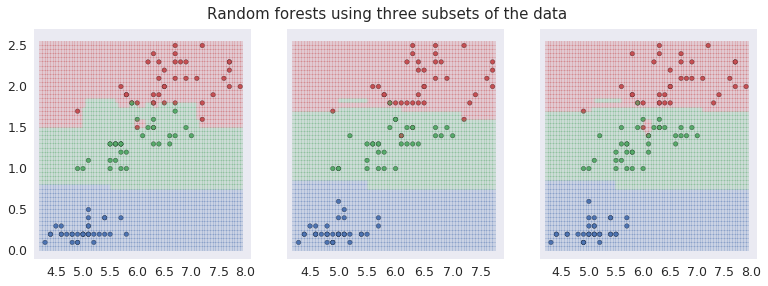
Using Random Forests to predict Iris species