Gradient boosting classifier
Tue, Sep 5, 2017This post has been adapted from this notebook on Gradient boosting.
Gradient boosting is a machine learning technique for regression and classification problems which produces a prediction model in the form of an ensemble of weak prediciton models, typically descision trees. The model is built in stages like other boosting methods where each stage fits the residual of the previous stage.
We first create a synthetic dataset from Hastie et al 2009, example 10.2.
# 5000 rows, 10 columns of X values with each column having
# a mean 0 and standard deviation 1
# Approximately half the y values are -1 and the other half are 1
from sklearn.datasets import make_hastie_10_2
X, y = make_hastie_10_2(n_samples=5000)
The table below shows the mean and standard deviations of the 10 columns
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| mean | -0.01 | 0.01 | -0.02 | 0.01 | -0.03 | 0.03 | -0.01 | 0.00 | 0.00 | 0.00 |
| stdev | 1.00 | 1.01 | 1.00 | 1.00 | 1.01 | 1.01 | 1.00 | 1.01 | 1.00 | 1.01 |
There is significant overlap of the y values as shown by the green and blue dots.
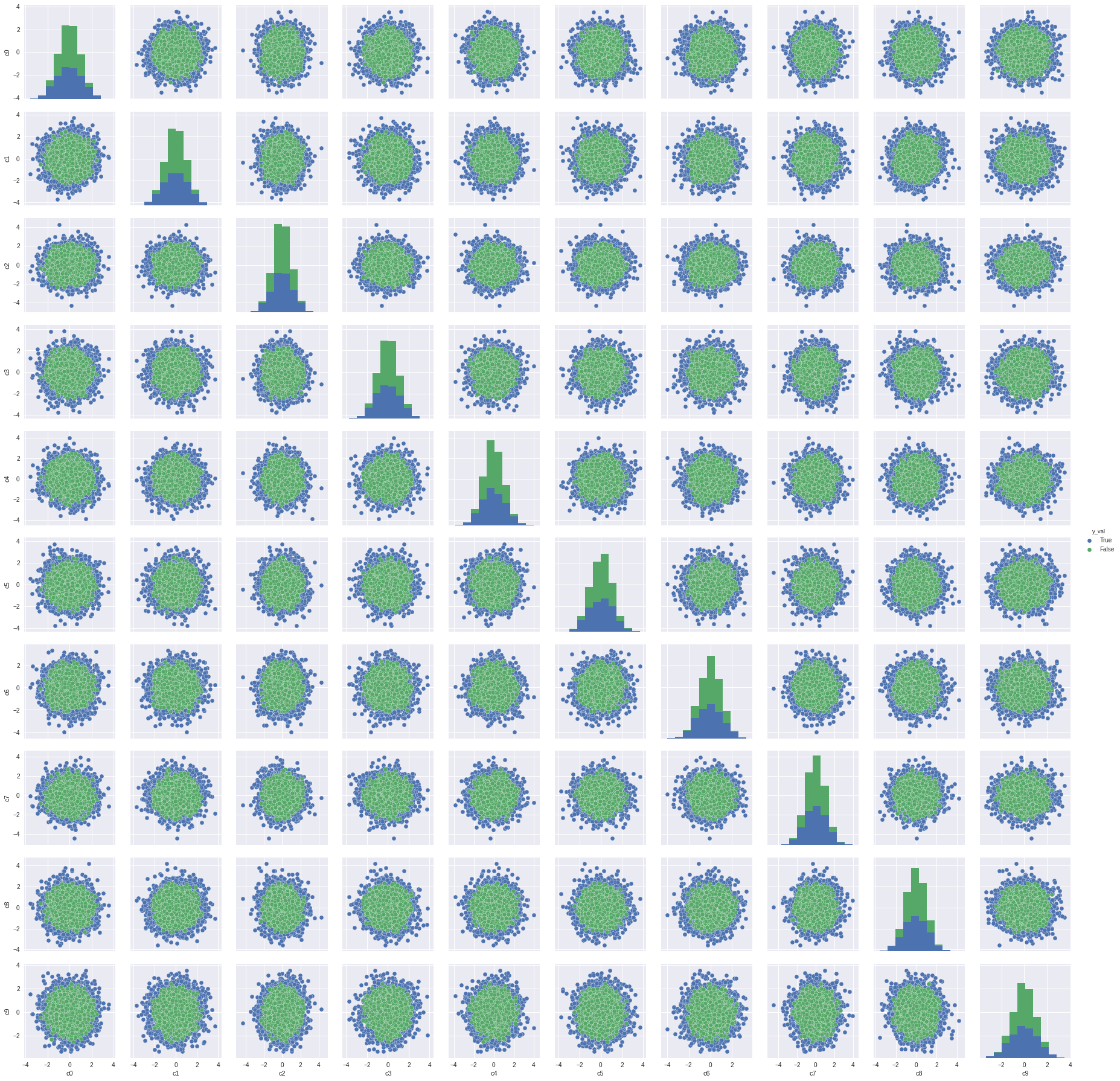
Pair wise plot
Applying the gradient boosting classifier we can estimate the accuracy.
# split the data into training and test samples
X_train, X_test, y_train, y_test = train_test_split(X, y)
# fit estimator
est = GradientBoostingClassifier(n_estimators=200, max_depth=3)
est.fit(X_train, y_train)
# predict class labels
pred = est.predict(X_test)
# score on test data (accuracy)
acc = est.score(X_test, y_test)
print('ACC: %.4f' % acc)
The importance of each of the 10 features is given below and all features are important.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| features | 0.09 | 0.10 | 0.10 | 0.10 | 0.11 | 0.10 | 0.10 | 0.11 | 0.10 | 0.10 |
The precision, recall and f1-scores are also high
| y val | precision | recall | f1-score |
|---|---|---|---|
| -1.0 | 0.90 | 0.93 | 0.91 |
| 1.0 | 0.93 | 0.90 | 0.91 |
All the source code is stored in a notebook